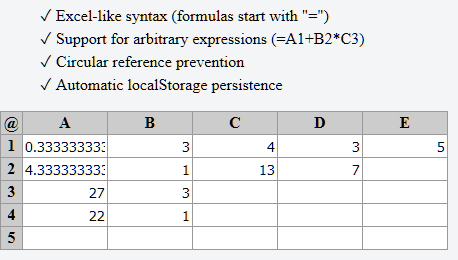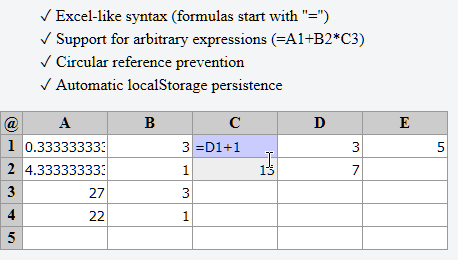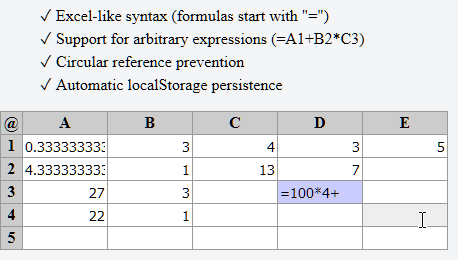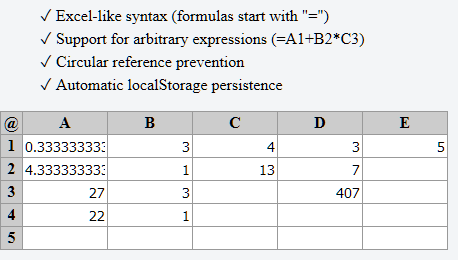
Latar Belakang
Pada kesempatan kali ini saya iseng luar biasa ingin membuat termometer yang tersambung ke cloud. Istilah kerennya, “Internet of Things.” Ide ini muncul karena akhir-akhir ini suhu udara tidak menentu. Terkadang saya gerah sekali ketika malam hari. Saya memiliki termometer “offline” yang selalu memberi tahu saya saat ini suhu udaranya berapa. Saya memiliki hipotesis, saya akan sangat gerah dan berkeringat luar biasa jika suhu udara di atas 32 derajat celcius dan saya akan merasa sejuk jika suhu udara di bawah 28 derajat celcius.
Untuk memvalidasi hipotesis saya, tentu saja saya perlu memiliki catatan berapa suhu saat ini pada setiap waktu. Sayang sekali, termometer offline seharga Rp30.000an ini tidak memiliki catatan. Andai ada sebuah termometer yang memiliki catatan dan disimpan ke berkas, itu akan sangat membantu. Akhirnya tercetuslah ide membuat termometer sendiri.
Peralatan
Saya mengikuti tutorial dari Adafruit mengenai cara membaca temperatur dengan Raspberry. Di tutorial tersebut, mereka menggunakan sensor DS18B20. Saya segera mencari sensor tersebut di Bukalapak. di sana kita akan menemukan banyak produk, tetapi banyak pelapak yang tidak aktif juga. Saya kemarin membeli di lapak yang ini. Dan iya, harga sensornya Rp30.000an — sudah sama mahalnya dengan termometer offline yang saya beli.
Kemudian saya membeli breadboard di toko elektronik dekat kantor. Harganya Rp27.000. Saya juga membeli satu paket resistor Sparksfun di Famosa Studio. Dengan peralatan yang sudah siap di tangan, saya bisa mengikuti tutorial dari Adafruit. Skematik yang diberikan cukup straightforward. Tada, ini dia hasilnya.
!!!!!!!!!!!!!!!!!! photos goes here
Konfigurasi Raspberry
Selanjutnya adalah menyiapkan Raspberry. Saat itu saya mencoba dengan Raspberry generasi awal tipe B dengan memori 256 MB. Kemudian agar tidak lambat updatenya, saya memasang Raspbian versi terbaru ke SD Card dengan Win32DiskImager. Begitu saya tancap kabel power, Raspberry tidak tersambung ke jaringan. Bahkan dia tidak hidup, hanya ada 1 LED merah yang menyarah (power) dabntidak ada tanda-tanda kehidupan. Ups.
Penasaran, saya pindahkan SD Card ke Raspberry PI saya yang satu lagi yang berukuran 512 MB. Hidup! Ada aktivitas disk! Ada aktivitas jaringan, tetapi gagal saya ssh. Ups. Saya coba login manual dengan menancapkan kabel HDMI ke monitor dan menancapkan kabel keyboard USB. Usut punya usut, ternyata SSH daemon harus diaktifkan secara manual. Oh. Oke, perkara sederhana.
Meski demikian, saya masih penasaran mengapa versi terbaru tidak jalan di model 256 MB. Oleh karenanya saya coba memasang versi yang berbeda di SD Card dan mencoba menancapkannya di masing-masing Raspberry yang saya miliki. Berikut hasilnya:
| Model/Konfigurasi | 2016-03-18-raspbian-jessie-lite | 2017-01-11-raspbian-jessie-lite |
|---|---|---|
| Raspbery PI B (Gen. 1) 256 MB | Jalan | Tidak mau hidup, layar boot tidak muncul |
| Raspbery PI B (Gen. 1) 512 MB | Jalan | Jalan |
Hmmmm. Cukup. Aneh. Entah saya yang terburu-buru, atau memang ada galat di versi terbaru. Saya tidak yakin yang terakhir. Tapi saya sudah melakukan rewrite berulang-ulang ke SD Card saya dan hasilnya sama saja. Oke, kita settle-kan saja dengan yang 512 MB dulu.
Tutorial dari Adafruit cukup straightforward. Akan tetapi script Python nya terlalu panjang untuk saya. Saya akhirnya membuat Bash Script sederhana seperti ini:
$ cat worker.sh
#!/bin/bash
TARGET=$(find /sys/devices/w1_bus_master1/28* | grep w1_slave)
TEMP=$(cat $TARGET | grep -o 't=.*')
echo "Temperature reading is: $TEMP"
Mari kita lihat hasilnya
$ bash worker.sh
Temperature reading is: t=29250
Woow berjalan dengan sempurna! Baiklah, seharusnya, saya tinggal membuat Cronjob kemudian menyimpan hasilnya ke berkas file. Jadilah sebuah pencatat temperatur. Kendati demikian, saya ingin membuat hal yang lebih menarik yaitu menyambungkan perangkat ini ke Cloud. Oleh karena saya malas membuat basis data yang kompleks, saya memilih untuk menggunakan Git saja.
Sementara, hasil bacaan dari temperatur dapat dilihat pada akun Github saya:
Btw, ini hasil rangkaiannya. Tidak jauh berbeda dengan yang ditunjukkan oleh Adafruit:

Yak, begitulah.