Mari bicara gaji. Eits, tunggu dulu, bukannya rahasia?
Bukannya berbahya memberi tahu gaji kita ke orang lain?
Nanti kalau orang lain jadi suka pinjam uang ke kita,
bagaimana? Ah, tentu saja dalam konteks lokal, rasanya
sangat jarang untuk bicara tentang gaji. Akan tetapi,
sesungguhnya bicara tentang gaji bisa bermanfaat.
Karena… ini ada hubungannya dengan ketimpangan gaji. Salah
satu upaya untuk melawan ketimpangan gaji adalah…
membicarakannya. Pada kasus ekstrim, membicarakan gaji
adalah lelucon. Akan tetapi, tempat kerja Anda tentu
bukan lelucon, kan?
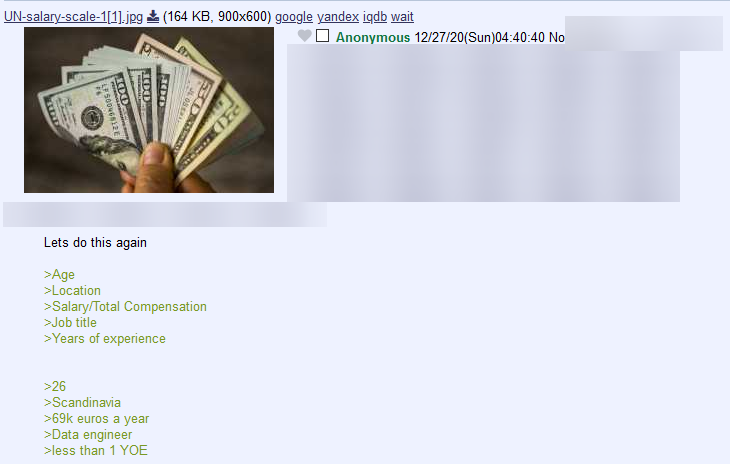
Di salah satu papan gambar, sesekali ada utas tentang
berapa gaji kita. Tayangan di bawah adalah salah satu
contoh utas di papan gambar. Saya tidak tampilkan ID
dari papan gambar ini karena mungkin terlalu “vulgar”.
Kalau kita bisa berbohong di papan gambar tanpa nama,
ada juga upaya untuk membahas gaji di Twitter. Dulu,
sempat ngetren pembahasan gaji lewat tagar TalkPay.
Sebentar sebentar… bukannya orang bisa berbohong?
Tentu saja. Di level yang lebih “gila”, Anda mungkin
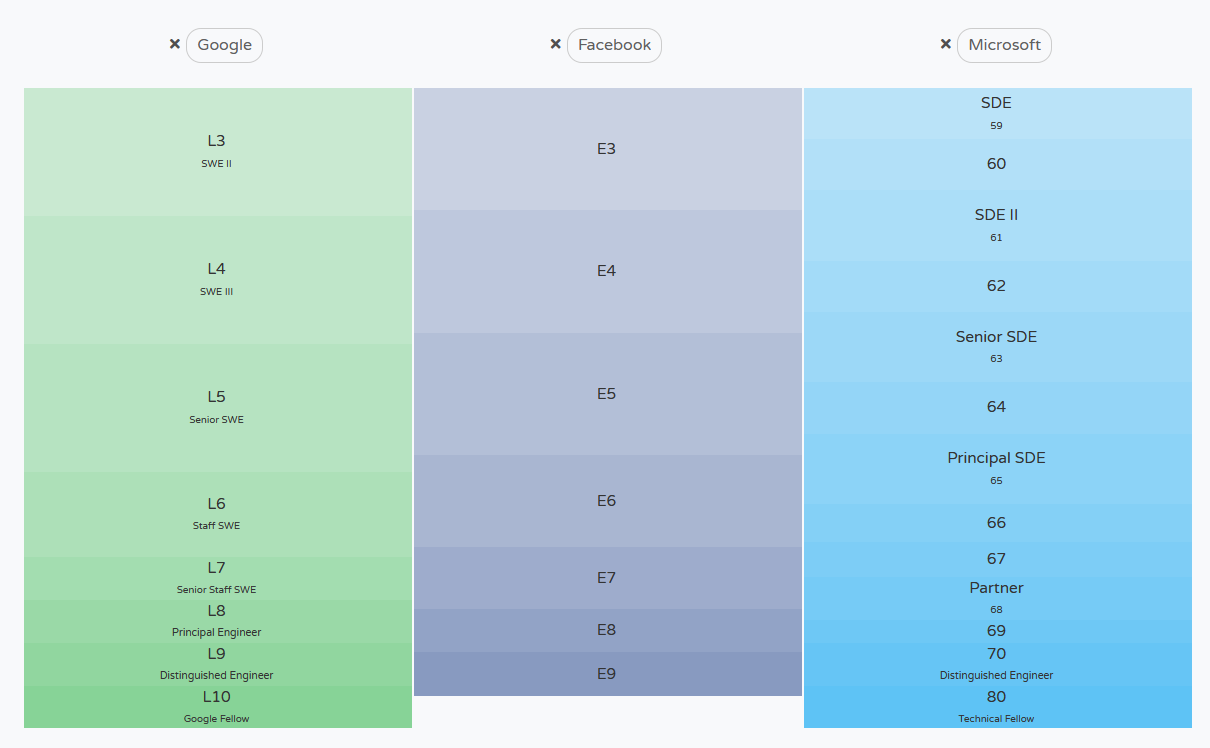
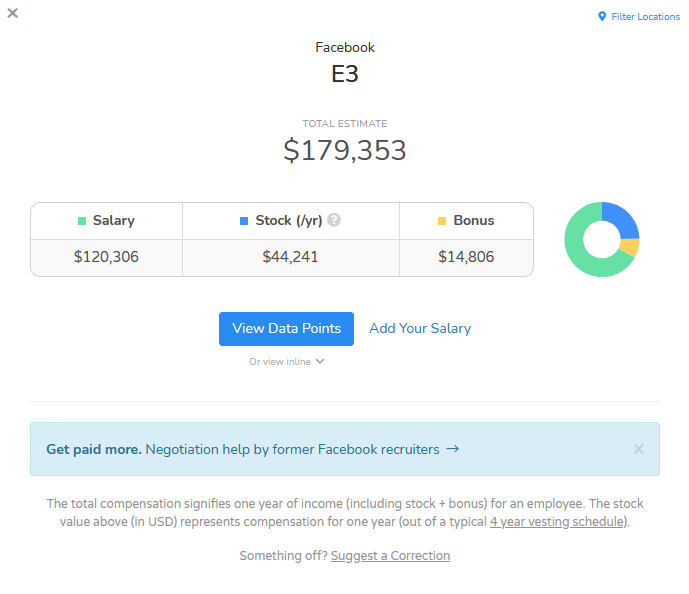
tertarik untuk melihat levels.fyi.
Levels.fyi disebut gila karena… metode verifikasinya
dia adalah dengan harus mengirim bukti pajak untuk gaji!
Anda diharuskan mengirim formulir W2 ke levels.fyi.
Wow?? Apa enggak ngeri tuh?
Saya kurang paham konteks kerahasiaan gaji di Amerika Serikat seperti apa.
Akan tetapi, gaji kita sebenarnya enggak rahasia-rahasia amat.
DJP tahu penghasilan kita berapa.
Bank juga tahu penghasilan Anda berapa, karena jumlah pendapatan
bulanan adalah salah satu syarat kolom yang wajib diisi dalam
pembukaan rekening. Penyedia jasa kredit, baik itu kartu kredit
atau kredit online atau kredit berbasis aplikasi, juga tahu
berapa gaji Anda karena itu dibutuhkan untuk verifikasi.
Boleh jadi bahkan Anda mengirim bukti pajak dan slip gaji ke
lembaga non-bank tersebut. Iya, non bank.
Di Indonesia banyak upaya serupa untuk bicara gaji dan
melawan ketimpangan gaji. Qerja telah
melakukannya sejak lama. Akan tetapi, sedikit sekali data di Qerja
yang bermakna. Ada juga upaya lain lewat sebuah
Tweet Viral
yang datanya terlihat lebih sound untuk pekerja IT.
Meski demikian, semua data yang bisa kita dapatkan untuk konteks Indonesia tidaklah
bisa diverifikasi. Kita tidak tahu berapa banyak orang
yang jujur dan berapa banyak orang yang berbohong. Malah
ada yang mengatakan data yang muncul di situs Qerja agak
condong ke persentil 30. Artinya, di bawah rata-rata. Besar
kemungkinan ketimpangan di sana.
Bagaimana dengan Survei Kelly?
Saya tidak tahu, data itu masih kurang bermakna. Bandingkan dengan levels.fyi.
Di sana secara persis digambarkan jenjang karirnya, ada apa saja
tingkatan karirnya, dan berapa gaji rata-rata untuk tingkatan karir tersebut.
Data ini tersebar secara ambigu di survei Kelly.
Berapa gaji sebenernya yang harus kita dapatkan? Berapa
gaji orang lain untuk tahun pengalaman yang sama? Kita
tidak tahu persis. Banyak sekali persoalan dalam ketenagakerjaan
yang perlu diperbaiki. Saya pikir, jika kita lebih berani
bicara tentang gaji kita berapa, kehidupan kita akan lebih
baik. Saya mengharapkan adanya platform seperti levels.fyi.
Jika kita rela memberikan data keuangan yang paling rahasia
kepada berbagai macam institusi finansial, mengapa kita
juga tidak berbagi data keuangan kita untuk memberikan
sedikit tambahan keberuntungan hidup kepada orang lain?
Ahh tapi kan dengan mengirim slip gaji belum tentu
datanya akurat? Mungkin perlu saya perjelas: akan lebih
baik jika kita berani berbagi informasi gaji dengan
data yang akurat. Di sana ada satu yang jelas: data
yang dikirimkan akurat. Tidak ada kebohongan di dalamnya.
Ya kalaupun ada, itu itikad buruk. Siapapun juga bisa
memalsukan slip gaji agar lolos KPR.
Tapi kalau pun mengirimkan data yang sahih, bukankah
masih mungkin datanya condong ke persentil rendah atau
persentil tinggi? Memang pasti dapat median? Ya bisa saja.
Lebih lanjut lagi, bisa saja gaji developer bimodal.
Sebagaimana gaji lawyer di Amerika Serikat, bimodal.
Membingungkan? Oh iya jelas, namanya juga curhatan
tidak terstruktur. Singkatnya, tolonglah ada semacam
platform seperti levels.fyi di Indonesia. Masa iya yang
punya data gaji yang akurat hanya petugas pajak, pekerja
bank, dan sales kredit? :D